
Ten minutes on asynchronous callbacks in JavaScript

Judith
February 9, 2019
Do you ever get the feeling that your brain has too many tabs open? Whenever I try to accomplish several things at once, I realize that I’m not very good at multitasking. Deciding which task should come first and what’s up next can be quite a challenge sometimes. As developers, we need to coordinate in advance whatever our program is supposed to do. How do we take care of all the „first… then… after thats“ that may come up on runtime?
Synchronous Functions
So here’s my claim: any time we write our program’s code, we’re actually architects, sketching out blueprints for everything that’s supposed to happen on runtime. A program may run so fast that it seems like lots of things happened at the same time. But if we slow its execution down, all we really see is the engine executing one statement after another. The engine just sticks to its blueprint very diligently. Line by line, it will run through the source code. Everything that needs to be taken care of lands on the engine’s “to-do“ stack. I’d like to illustrate this with this blueprint for a program that uses functions to log out strings.
Let’s execute this code to see what is happening in the background. We are going to pretend we could press a pause button while the program is actually running. We are also going to assume that “first” and “second” has already been logged out on our screen. This is the exact point in time when we stop the engines. If we take a glimpse behind the screen, we might see something like this:

At this exact point in time, our third function pops up on the call stack. The engine is tending to that one right away.
So here we have our source code and the engine that’s already busy with a stack of code chunks (the call stack).
Our source code, or blueprint, contains all the necessary instructions. On runtime, it is broken down into digestible chunks of code. The one important thing to remember is that each function is just one of those code portions. Whenever a function is called, its code chunk pops up as a new portion on the engine’s call stack. The engine is not a multitasker. It always gets busy with whatever lands right on top of its code stack. So here, it is currently digging right into the newly added code chunk (the function third()) in order to strictly run the function’s code line after line. And when the engine has finished up this function, it stoically continues executing the remaining code portions on its call stack one by one. From top to bottom, one line at a time. Here’s what we mean when we speak of synchronous code:
Synchronous Code If we have two lines, say line 1 and line 2, the second one won’t start running until the first one’s execution has finished.
Synchronous Callbacks/Executors
You probably already know that functions are first-class citizens, so they can be arguments for another function. The fact that we can pass functions around is an essential feature of JavaScript. A typical scenario might look like this:
Whether you have .map(), or .forEach(), or .filter(): all JavaScripts standard library methods are synchronous (the only exceptions: .setTimeout() and .setInterval(), which are not part of the standard library but belong to an external API). In this example, the function sent along (x => x * 2) is executed immediately, and also repeatedly. For every element of the array, our function pops up on top of the call stack, where our engine takes care of it right away. And console.log() will be run after our .map() method has finished all its loops.
You probably know that “functions-that-are-passed-over” are referred to as “callbacks”. I find the name a bit misleading and I like to get my terms right, so bear with me: as long as we speak of synchronous code, let’s just stick to executors instead of callbacks from here. You’ll see in a minute that asynchronous callbacks work in a different way.
Asynchronous Functions
Sometimes, we need to instruct the engine to start a process that is time-consuming. Whenever we ask it to read files in order to use their data later on, for example. Or when we ask a third party if they could process an image or look up some information. If our program sends out these kinds of requests, we don’t know how long it will take until the response is available.
Remember: our app is still single-threaded. It still cannot do multitasking, it won’t perform tasks simultaneously. But it can start off concurrent tasks by delegating duties. These actions can all be kicked off with JavaScript, but they are followed through by third party code or external APIs. Imagine our program saying to a server: “get me some data and return it to me“. Here we have an (imaginary) third-party function requestSync() which asks a server for the content of a website. This function is synchronous and makes our program wait patiently for the server’s reply before it can log out stuff.
That looks ok, doesn’t it? Well, it isn’t, not really. No matter how fast the external computer is with its calculations in the background: it takes time until the data is back and ready for our program to actually use it. This synchronous requestSync() just makes our program wait until the external server actually found and returned the data we requested. If we allow our program to freeze until we get some kind of result from third parties, we might slow it down immensely.
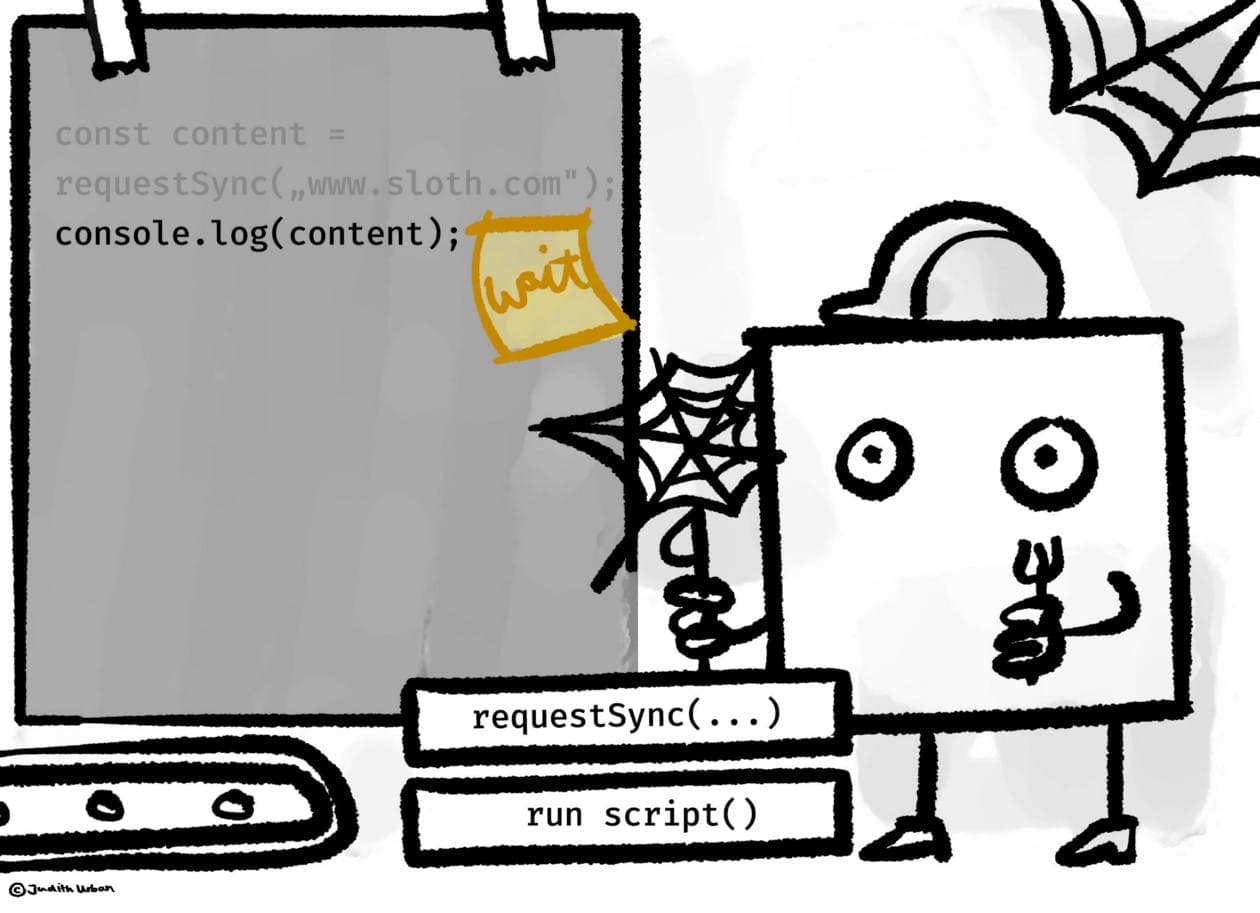
A frozen program.
Do you remember what it feels like when a website freezes right after you click a button, making every user interaction impossible? That’s what we did right there. Synchronous functions only get us so far.
You’ll have guessed already that we’ve finally reached the point where asynchronous functions come in. Here’s the definition:
Asynchronous Code Asynchronous code sends off instructions for tasks that take a while, like kicking off a third party background process. If we have two lines, line 1 (some asynchronous statement) and line 2, the second one will be allowed to execute before the first statement has actually finished its job. This is also called concurrency.
Our synchronous requestSync() just won’t do. We want another tool that is asynchronous so our program doesn’t have to wait. So we looked into it and actually found an (imaginary) asynchronous request() function. One that allows our engine to further execute the rest of the code on the blueprint. Cool! Let’s try it out.
Just when we thought we had found the solution for the ultimate question of life, the universe, and frozen code, we stumbled right into a topic that keeps developers on their toes on an everyday basis: Handling asynchronous tasks properly. Why did console.log(content) log out undefined? Executing the function request(), our engine asked the third party server to serve us some data. As soon as it has put out this request, our engine wraps up that function and is free to move on to the next line. So it executes the console.log… even though it hasn’t heard a thing from the server yet. Logging out stuff too early might not really be a big problem. But what if we have some follow-up code that actually needs the website’s data to run properly? How can we make sure our program doesn’t freeze but have our engine move on executing everything but certain chunks of code? And take care of those only after the data we need will have returned?
Asynchronous Callbacks
Let’s take another look behind the scenes, as there’s something we have missed until now. Our runtime environment has its own nice built-in conveyor belt: The task queue. It is built for cases where external processes that we can’t control are involved. Third-party code can put chunks of code on our task queue. Why is that useful? Because whenever we give a third party instructions for something asynchronous to happen, we can send along an “after-that-chunk-of-code”. We do that by sending along a callback function whenever we call asynchronous third-party-functions.
Whenever this chunk of code finally lands in the task queue, our engine will notice and say: „Cool! As soon as I’ve finished my current stack, I’ll take care of that chunk of code from the queue.“
Ok, if this gets a little hard to understand with all the tasks and queues, don’t worry. Back to our example: We’ll take our asynchronous request() method and see what happens if we pass the console.log(content) as a callback in the method’s argument chain.
The callback seemed to have worked. Here’s what happened, step by step: The function we’ve just sent along is handed over to the external program while our engine is able to continue executing. When the lazy server finally spits out its data, here’s what happens: the third party code calls the callback content => console.log(content) with the server’s data. That’s the moment when our callback lands right on our task queue. Remember: our engine still can’t do multiple things at once. Whatever it is currently busy doing when the package from the server is shipped back to our app: the engine first finishes up its call stack and only then takes care of the shipped callback task.

A new callback has arrived in the task queue. It will be dealt with when the call stack is empty.
Summary
It might not be so obvious in our everyday life, but the big difference between synchronous executors and asynchronous callbacks is all about what actually happens on runtime. Synchronous callbacks, or executor functions, pop up on the call stack to be taken care of right away.
By passing callbacks to asynchronous functions, however, our program sends out “to-do-later-chunks-of-code” to external parties. When the third party code has finished its time-consuming thing, it is supposed to call the callback so it appears on our own task queue. But here the callback has to wait its turn until our engine has its “hands” free again.
I hope that this article helped you understand why, until a few years ago, callbacks were the go-to solution for handling asynchronicity. Callbacks didn’t lead to a happily ever after, though. They have their own set of drawbacks. As we hand over our callbacks and allow for someone else’s code to finally put them on the task queue, we also give up a lot of control... But let’s save that for next time. Be around for part II, where I’ll explain why promises and async/await are such genius inventions.

Judith started an apprenticeship at Peerigon in 2018 to become a professional web developer. As part of her weekly routine, she publishes a blog post each week about what she has been doing and what she has learned.
JavaScript
Asynchronous
Callbacks
Call Stack
Tutorial
Read also

Nick, 05/27/2026
Frontend Performance Meets Green Coding
Green Coding
Green IT
Carbon Footprint
Sustainability
Energy Tracking
Cloud Efficiency
Web Performance

Irena, 03/11/2026
Robotics in Balance: How digital solutions make physical processes smarter
Industry 4.0
Digital process optimization
Data visualization
Modular robotics solutions
Automation
Predictive maintenance
Smart Factory Software

Philipp, 03/11/2026
From Excel chaos to competitive advantage: established processes as the perfect foundation for B2B portals
Digital Transformation
Process Automation
Data Management
Custom Software Development
Business Process Digitization