
User Input Considered Harmful

Leonhard
July 15, 2024
There is a library that has crept into our codebases over the last few years -- for the better. It's called zod and it has added both value and developer happiness to our projects. The project describes itself as a library for "TypeScript-first schema validation with static type inference".
In this post, we will dive into why and how we can use zod in the context of a full-stack web application powered by TypeScript.
Why Validate?
All user input should be considered harmful. There are two main things to consider:
- Invalid input: You have business requirements that require data to conform to a certain shape. For example, the "Email" field in the registration form should actually contain a syntactically valid email address. Invalid data can result in a broken application or simply useless output.
- Malicious input: You have probably heard of cross-site scripting (XSS) or SQL injection attacks - both still in the Top 10 Web Application Vulnerabilities. Similarly, you want to strip any extra fields from a payload before writing to the database - otherwise someone could overwrite a foreign key like owner_id to maliciously associate the record with their own user. One way to combat these attacks is to validate the data coming into your application.
These reasons are very product specific. So how does developer happiness fit into this? As developers, we like working with typed data. It makes our lives easier by providing us with autocompletion, type checking, and refactoring tools. However, defining types separately from the business logic can be cumbersome -- how should these be kept in sync? This is where validating data (or rather parsing, as we'll learn) can help us, too. After the data has been parsed, we can be sure that it is in the shape we expect.
Wow, that was quite technical. How might we visualize this?
You can think of parsing as the process of checking visitors at the gate of a castle. Before passing the gate, the visitor is unknown. We have to check them. If they match the schema (friendly merchants, inhabitants, ...), they can enter. Furthermore, we can assign them a specific role they carry with them from now on. This role is known throughout their time in the castle (our application). In the process of checking, we may take dangerous items away from them. However, if they don't match the schema (enemies, spies, ...), we can deny them entry and throw them out.
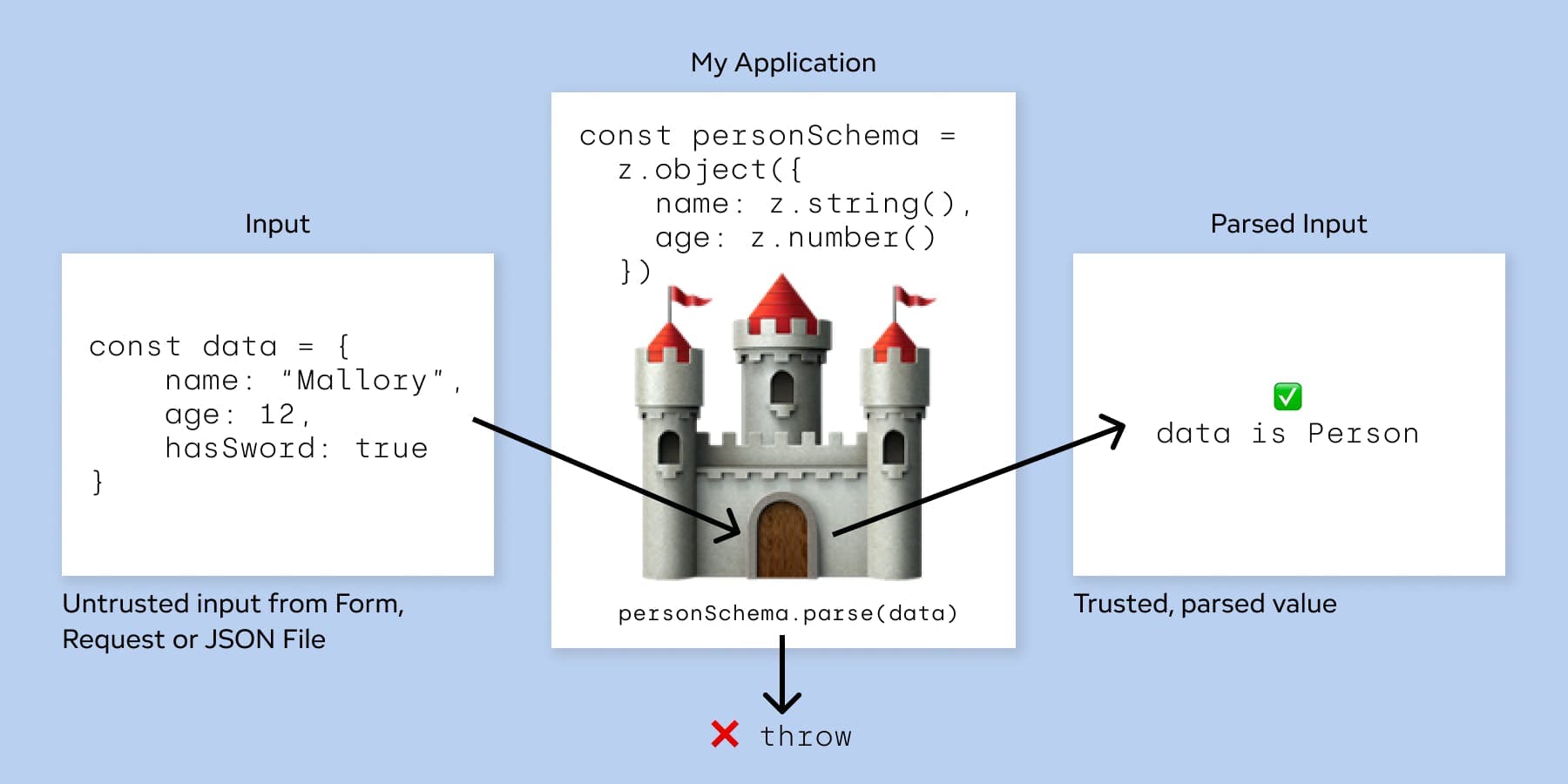
Enough talk. So how does this work with zod?
Basic Usage
Let's consider a basic schema to represent a person, consisting of their name and age:
So far, so easy!
But wait...why is the method to validate called parse()? This is because zod is not only about validating data, but also about parsing it. In fact, zod follows the idea of parsing, not validating. This means that it tries to parse the data according to the defined schema. If the data does not match the schema, parse() will throw an error. After zod parsed a generic object, it's given a specific TypeScript type it'll carry from now on -- great for further processing!
This is in contrast to sprinkling if statements throughout the codebase to check the value and shape of an object. Also these if statements are not easy to compose. Compare this to the example above where we chained the string() and min() methods or composed the personSchema from the legalAgeSchema. This is a powerful concept that can be used to build complex schemas from simple building blocks.
Full-Stack Application
In a full-stack application, you can use zod in both the front-end and the back-end. Usually it makes sense to define the schema in a shared package in the monorepo.
The frontend would use the schema to parse the form values before sending it to the backend. This way the frontend can provide immediate and actionable feedback through field error messages or toasts to the user, a nice user experience.
The backend would parse the incoming request body. Using convenience methods such as extend(), the backend can add additional fields to the shared schema. For example, the backend could add a generated id field to the data or extract the user_id from the authorization context.
Parsing should be done at the gate of our castle, the system boundary, as early as possible. All further code can then rely on the type information -- getting us one step closer to full-stack type safety.
Example: Search
Let's consider an application for searching for a JavaScript package. The user may be able to enter a search query, choose the registries to search in and select the number of results per page:
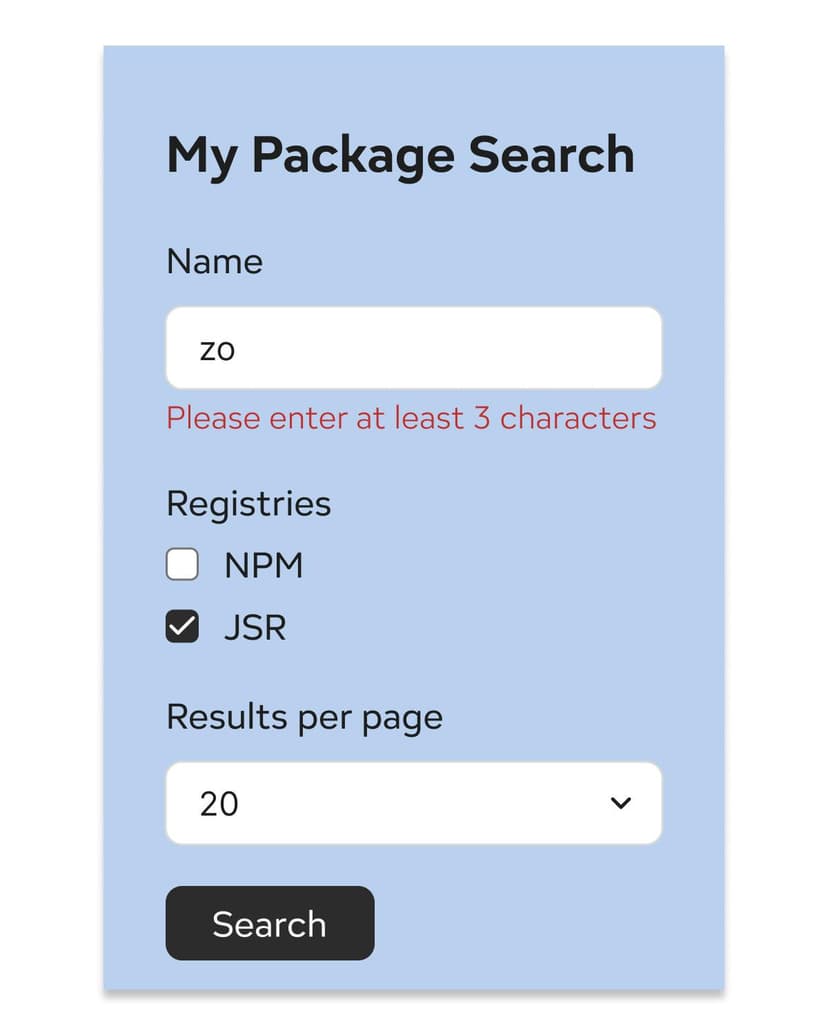
With zod, we can define a schema which describes the shape of the object we are expecting.
You could say that the schema acts as the contract between the frontend and the backend. When both frontend and backend adhere to the same contract, both parts will work together. Happy life in the castle!
Parsed, Inferred, Delivered
We have barely scratched the surface. There are other types of user input you should consider, such as URL search parameters or web hook payloads. There are also zod-inspired libraries that put schemas front and center. For example, in tRPC you can define input (for Request) and output (for Response) schemas to write fully type-safe applications. Sometimes you may need asynchronous validation. For example, you may want to validate a user's email address by checking if it is already in use -- an async database query. zod allows you to do this using refine() and parseAsync().
There are many similar libraries to zod. It was simply one of the first with great TypeScript support and has since gained a large following. An interesting alternative is valibot, which aims to reduce bundle size by allowing your bundler to effectively treeshake the library functions used.
In the end, it doesn't matter how you validate. What matters is that you do take care of data validation (or rather parsing) in your application. For both added project value and developer happiness.
🤖 Statement about usage of AI in this article: This article was written by humans (thanks for the feedback Irena & Johannes!), including the title, concepts, code samples. However we used AI to enhance the style of writing.
Header Photo by Ümit Yıldırım on Unsplash
TypeScript
Web App Development
Best Practices
Full-Stack
Validation
Read also

Irena, 03/11/2026
Robotics in Balance: How digital solutions make physical processes smarter
Industry 4.0
Digital process optimization
Data visualization
Modular robotics solutions
Automation
Predictive maintenance
Smart Factory Software

Philipp, 03/11/2026
From Excel chaos to competitive advantage: established processes as the perfect foundation for B2B portals
Digital Transformation
Process Automation
Data Management
Custom Software Development
Business Process Digitization

Niklas, 03/09/2026
Are Passkeys Ready for Prime Time? – The Security Perspective (Part 1)
Passkeys
Passwords
Passwordless Authentication
Public-Key Cryptography
Challenge-Response Authentication